随着深度学习模型参数量越来越大,如何使用多卡并行训练模型加速训练是机器学习系统需要考虑和优化的重点。多卡并行训练涉及到多张卡上的模型参数和梯度汇聚和分发,而多卡之间的通信带宽往往是有限的,如何设计一个高效的汇聚和分发算法最大化地利用这些通信带宽以提升训练效率是一个值得研究的问题。本文将从最为简单的多卡训练模型出发并分析其缺点,然后再介绍一种名为 Ring Allreduce 的算法是如何解决这些缺点的。
1. 传统多卡并行
假设我们使用 N 张 GPU 进行并行训练,每张 GPU 上的模型梯度大小为 K。在深度学习训练中,我们需要求所有 GPU 上模型梯度的平均值再利用梯度下降算法进行训练。为了实现这一目的,最简单的并行方式就是我们指定一张 GPU 为 master GPU(为了方便讨论,这里指定为 GPU 0),其余的 GPU 为 slave GPU。在模型的反向传播后,将每张 GPU 上的梯度在 master GPU 上进行汇聚(在这里就是求平均值),然后将梯度的汇聚结果从 master GPU 上发送到其余的 slave GPU。具体过程如下图所示:

这里,我们计算一下每张 GPU 上需要发送和接收的数据量大小:
- 对于 master GPU(这里是 GPU 0):
- 由于其余所有 slave GPU 都需要发送完整的模型梯度给 master GPU,所以其接收的数据量为 (N-1) * K。
- master GPU 还需要将汇聚的梯度发送到 slave GPU,所以其发送的数据量也为 (N-1) * K。
- 对于每个 slave GPU:
- 发送和接收的数据量均为 K。
这种并行方式有两个缺点:
- master GPU 和 slave GPU 的通信量不一样,然而在实际中 GPU 之间的通信带宽一般是相差不大的。在这种情况下,master GPU 会成为一个通信瓶颈,其它 slave GPU 传输数据到 master GPU 会发生拥堵。
- 每个 GPU 的工作量是不均等的,在 slave GPU 将模型梯度发送到 master GPU 后, master GPU 需要对 slave GPU 求平均值,而 slave GPU 不需要进行这一步,只能空转浪费时间。
PyTorch 中的 torch.nn.DataParallel 就是采样这一方式在 GPU 间汇聚和发送梯度的,因此在GPU 数量较多的情况下其加速比会远低于 N。
2. Ring Allreduce 多卡并行
为了解决上面两个缺点,在2017年,百度引入了高性能计算领域中著名的 Ring Allreduce 算法,其能够平均每张 GPU 的通信量和工作量。在该算法中,所有 GPU 将组成一个环,每个 GPU 都有其左邻居 GPU 和 右邻居 GPU(如下图所示)。算法共包括两个不同的步骤,分别为 scatter-reduce 步骤 和 allgather 步骤,下面将会对这两个步骤进行阐述。

scatter-reduce 步骤
为了保证每个 GPU 通信量和工作量尽可能相等,模型的参数首先被划分为大小相等的 N 个数据块,然后将每一数据块通过 N-1 次数据传输将其汇聚到一个 GPU 上。具体算法如下,在每次数据传输中,每块 GPU 将向其右邻居发送一个数据块,并从其左邻居接收一个数据块并进行汇聚操作(如下图所示)。
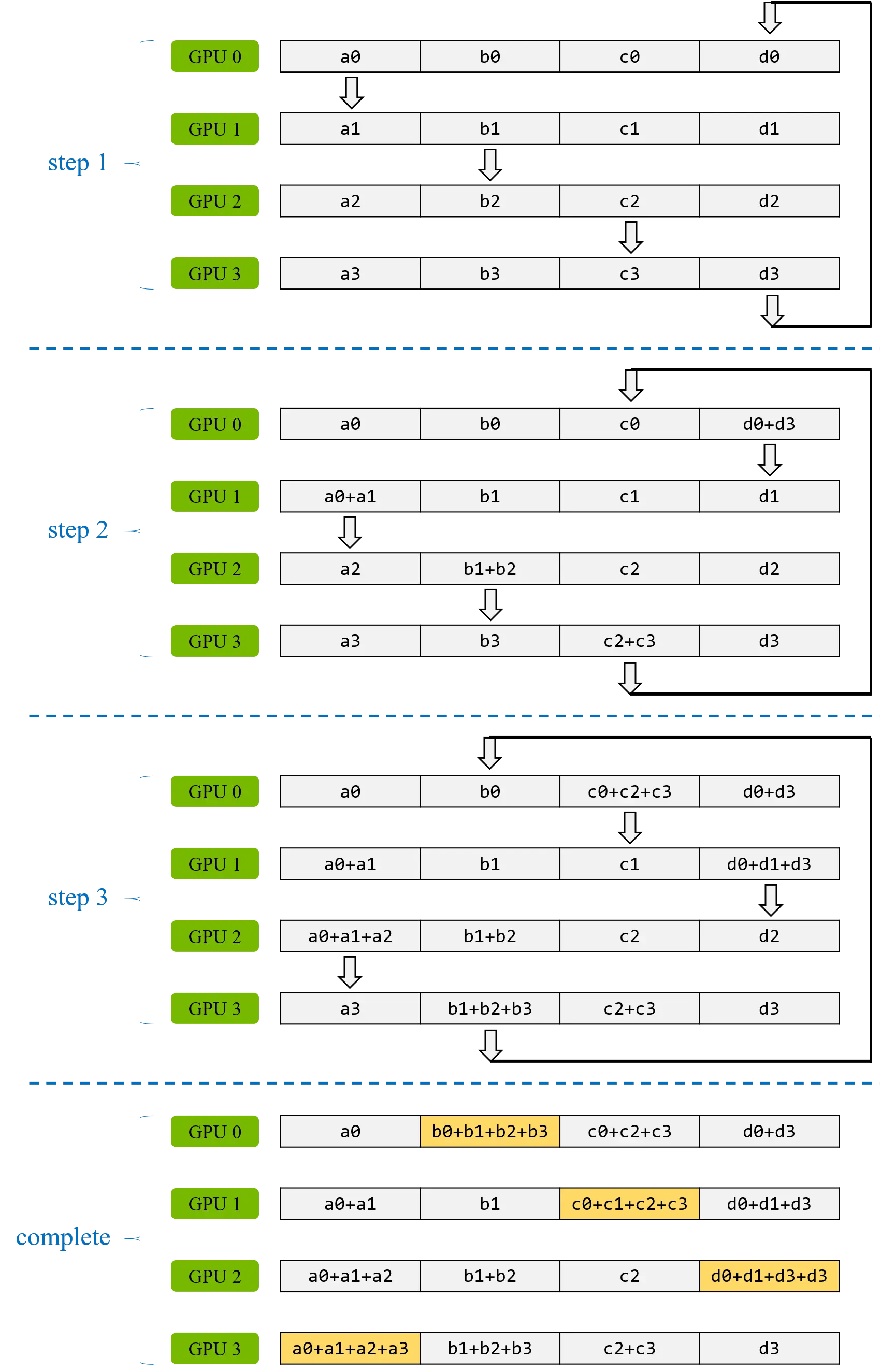
allgather 步骤
在完成 scatter-reduce 后,每块 GPU 上都有一个数据块已经汇聚完其余所有 GPU 上的值(即上图中最后一步中每个 GPU 中的黄色数据块)。接下来我们进行 allgather 步骤将这些黄色数据库发送到其他 GPU 上,总计也需要 N-1 次数据传输。具体做法和上述 scatter-reduce 步骤是非常相似的,每块 GPU 将向其右邻居发送一个数据块,并从其左邻居接收一个数据块并覆盖当前 GPU 对应的数据块(如下图所示)。
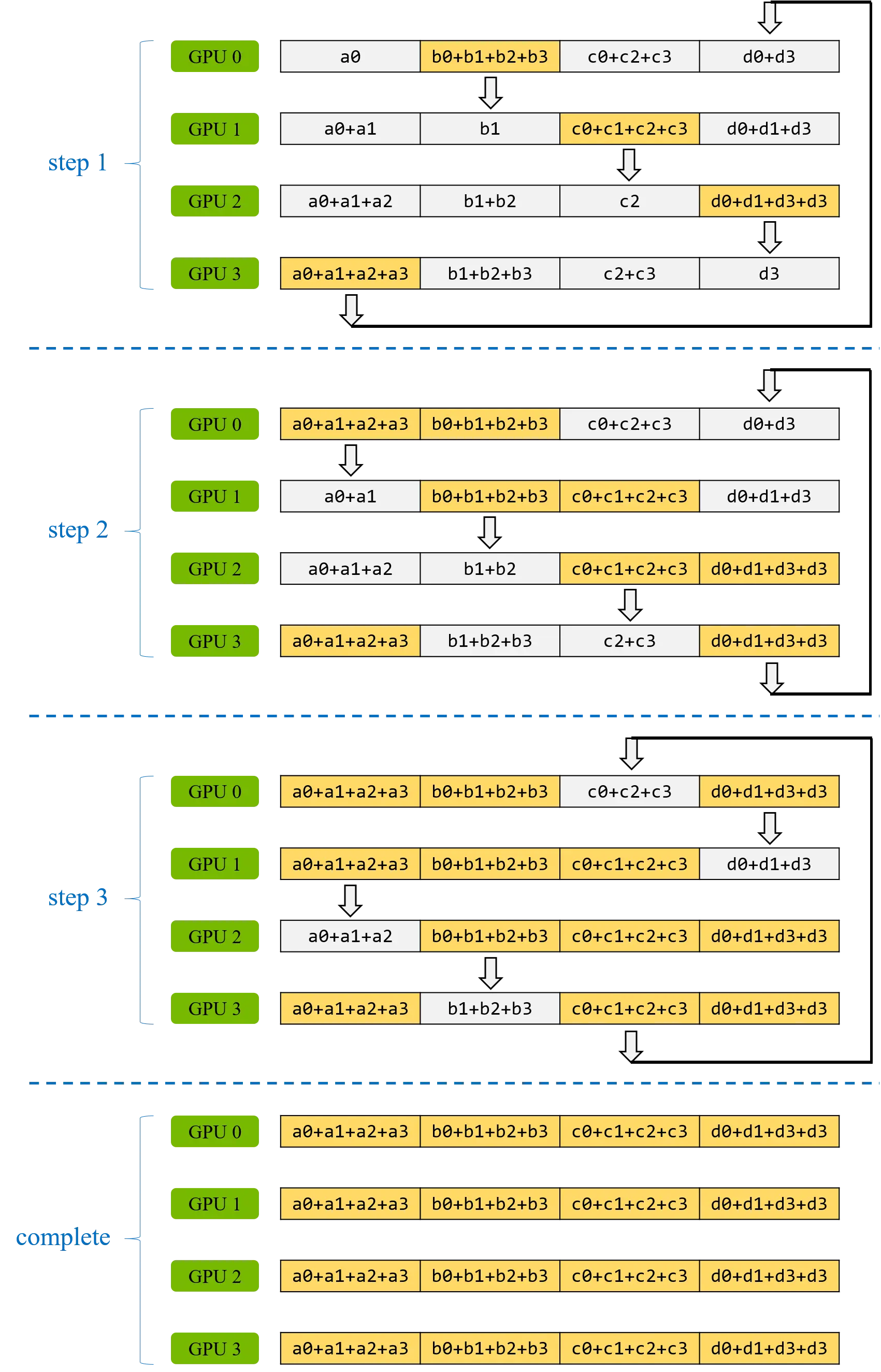
下面我们计算一下每块 GPU 的通信量,在 Ring Allreduce 算法中每块 GPU 都是对等的,因此每块 GPU 的通信量大小都是一样的:
- scatter-reduce 步骤:每块 GPU 从左邻居接收 K/N 的数据,向其右邻居发送 K/N 的数据,重复 N-1 次。
- allgather 步骤:和 scatter-reduce 步骤的通信量相同。
经过计算,每块 GPU 发送和接收的数据量均为 (N-1) * (K/N),因此传输到每个GPU和从每个GPU传输的数据总量为 2* (N-1) * (K/N)。
从通信量的计算分析中,我们可以得到:
- 每块 GPU 的通信量与 GPU 的数量 N 无关,这说明 Ring Allreduce 所构建系统的吞吐量有可能随着 GPU 数量 N 呈线性拓展。
- 整个算法受限于 GPU 环中最慢 GPU 通信连接,因此需要仔细地构建 GPU 环以达到最优的带宽配置。一般来说,如果使用多节点训练,因节点内部 GPU 间的带宽会显著高于节点间的带宽,因此每个节点上的 GPU 应当在环中彼此相邻以达到最优的配置。
再回过头看 Ring Allreduce 算法是怎么解决传统多卡并行中的两个缺点,第一,每块 GPU 的通信量是一样的,不存在某块 GPU 是通信瓶颈这一问题;第二,每块 GPU 均会参与汇聚运算,且工作量相等,不存在某些 GPU 处于空转的问题。PyTorch 中的 torch.nn.parallel.DistributedDataParallel 就是采用了 Ring Allreduce 算法,其在 N 不是特别大的情况能够达到很好的加速比。