
深度学习中的 Ring Allreduce 算法
随着深度学习模型参数量越来越大,如何使用多卡并行训练模型加速训练是机器学习系统需要考虑和优化的重点。多卡并行训练涉及到多张卡上的模型参数和梯度汇聚和分发,而多卡之间的通信带宽往往是有限的,如何设计一个高效的汇聚和分发算法最大化地利用这些通信带宽以提升训练效率是一个值得研究的问题。本文将从最为简单的多卡训练模型出发并分析其缺点,然后再介绍一种名为 Ring Allreduce 的算法是如何解决这些缺点的。 1. 传统多卡并行假设我们使用 N 张 GPU 进行并行训练,每张 GPU 上的模型梯度大小为 K。在深度学习训练中,我们需要求所有 GPU 上模型梯度的平均值再利用梯度下降算法进行训练。为了实现这一目的,最简单的并行方式就是我们指定一张 GPU 为 master GPU(为了方便讨论,这里指定为 GPU ..
更多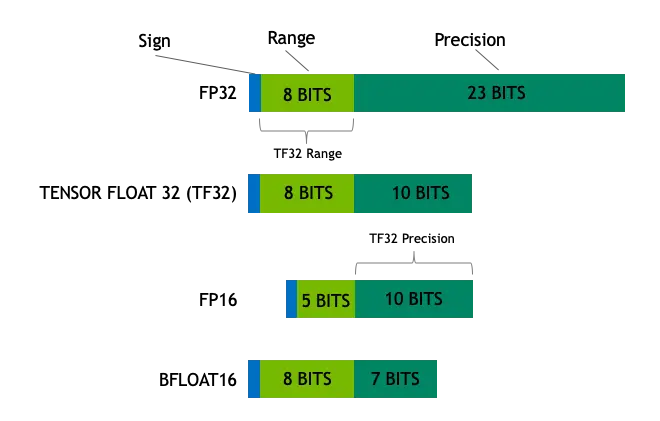
深度学习中的TF32和BF16格式
在深度学习中,数值表示是一个常常被忽略的内容,可能从事模型量化领域的研究人员会有所了解,但是大部分的研究人员都对其了解甚少。但是一个设计合理的数值格式能够更好地加速模型训练和推理,在深度学习的工业化和实际落地中是非常重要的。近年来,为了加速深度学习,进一步挖掘硬件的性能,业界发明了一些新的数值格式,如本文中所介绍的TF32和BF16格式。其主要思想是利用深度学习对表示范围敏感而对精度不敏感这一特性,重新设计浮点数的表示,达到了一个更加好的平衡。 1. 单精度浮点数格式FP32(背景知识)在深度学习中,单精度浮点数格式 FP32 是一种广泛使用的数据格式,其可以表示很大的实数范围,足够深度学习训练和推理中使用。这种格式使用4个 bytes(32bits)表示,其示意图如下。这 32 bits共分为3个部分: ..
更多
Meltdown 漏洞
Meltdown又名为恶意数据缓存加载漏洞,其存在于大多数现代处理器中,该漏洞可以使得用户态进程读取内核空间中的内容。本文将对其大致原理进行解读,其中的细节并不会过度涉及,稍有计算机底层基础知识的同学即可放心食用。 1. 背景知识首先先来回顾一下计算机的基础知识,可以帮助更好地理解Meltdown漏洞。 乱序执行(来自维基百科): 在计算机工程领域,乱序执行(错序执行,英语:out-of-order execution,简称OoOE或OOE)是一种应用在高性能微处理器中来利用指令周期以避免特定类型的延迟消耗的范式。在这种范式中,处理器在一个由输入数据可用性所决定的顺序中执行指令,而不是由程序的原始数据所决定。在这种方式下,可以避免因为获取下一条程序指令所引起的处理器等待,取而代之的处理下一条可以立即执..
更多